Downloading a .csv file is one of the most common ways to obtain data from marketing platforms such as Google Ads and Meta Ads. CSV stands for comma-separated values.
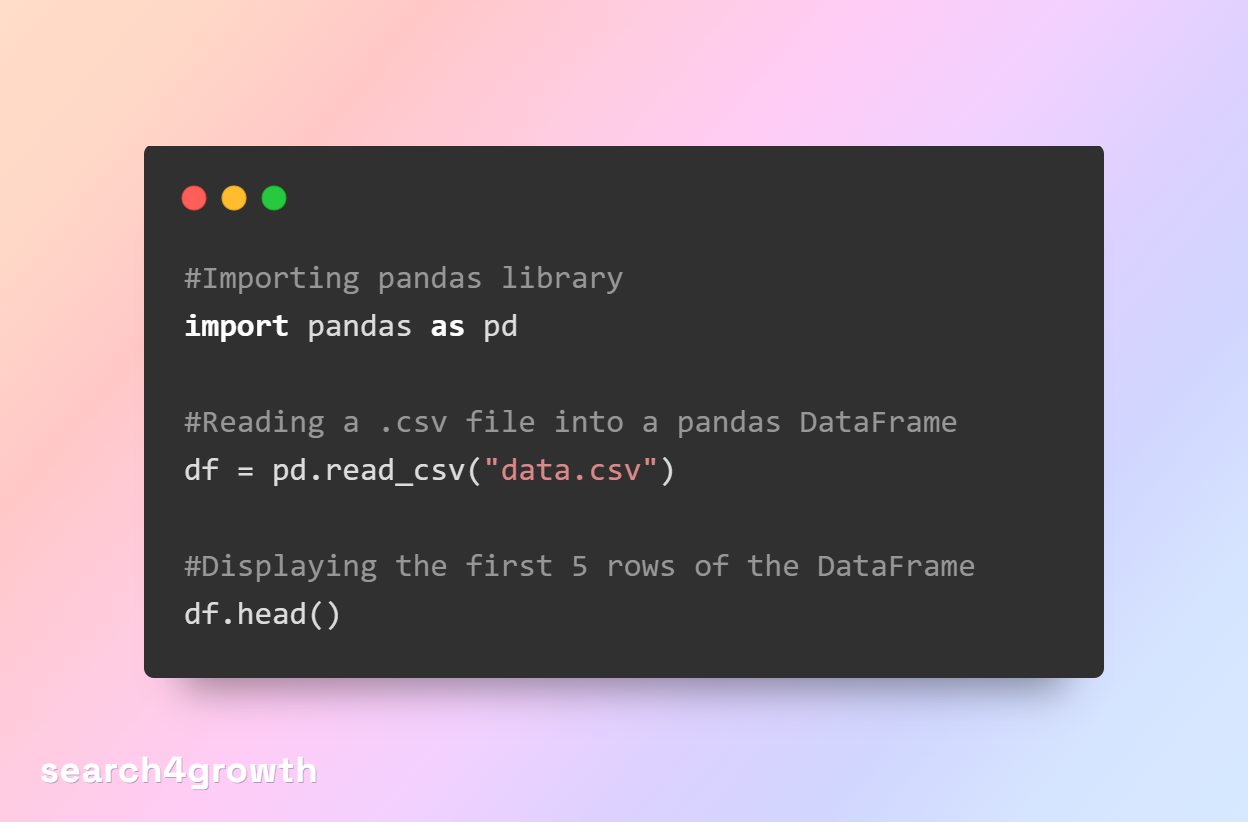
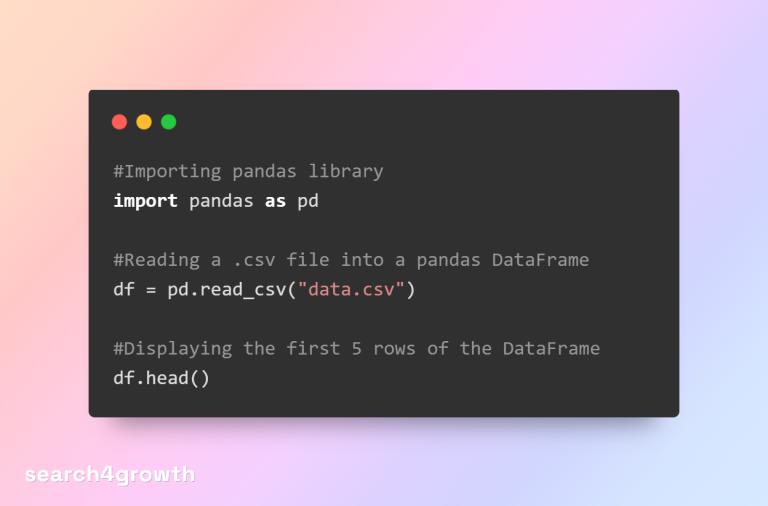
The Python pandas library provides the read_csv method to create a DataFrame from a .csv file. Once you have a DataFrame object, you can explore and manipulate the data using Python.
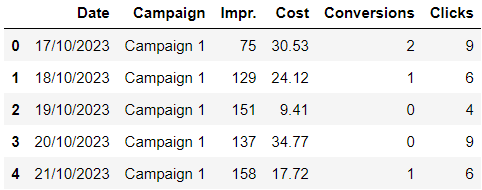
The above code will show the top 5 rows of the imported data.
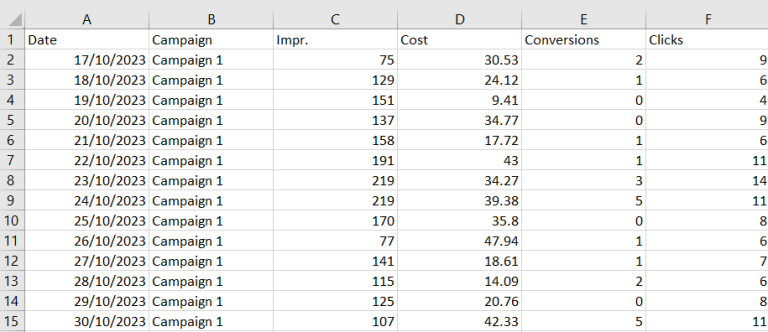
In this example, the original .csv file contains column names in the first row.
Reading a .csv File Exported from Google Ads
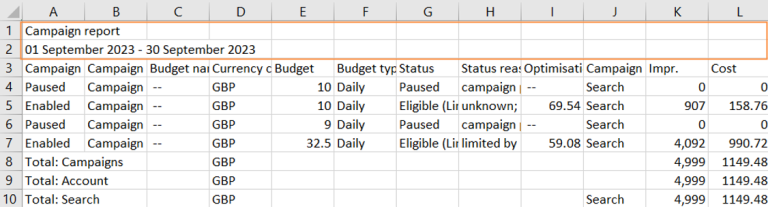
Now, let’s consider a scenario where we use a file exported from Google Ads, which includes two additional rows at the top of the .csv file.
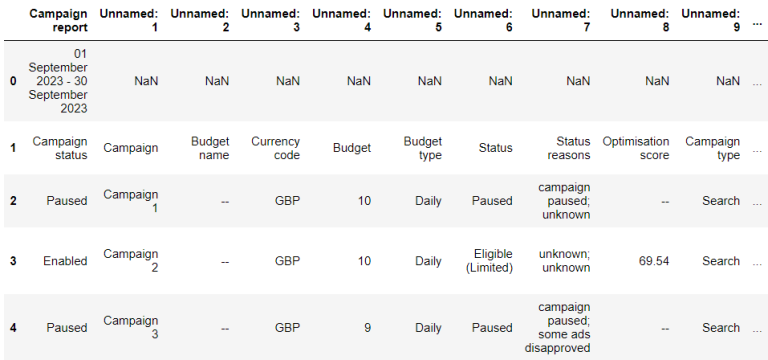
The result of the previous code will look like this:
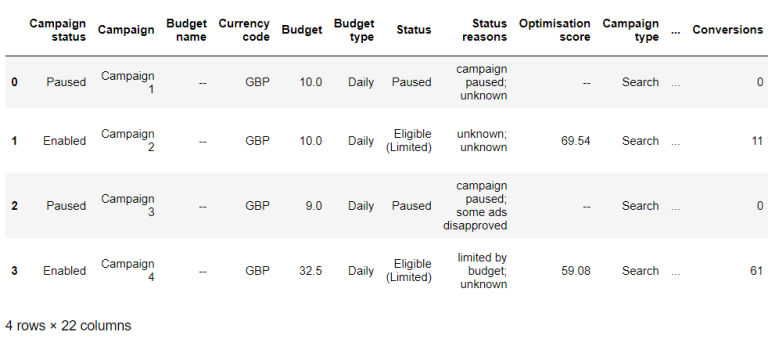
The column names were not parsed properly. An additional parameter skip rows = 2 can help to resolve this issue.
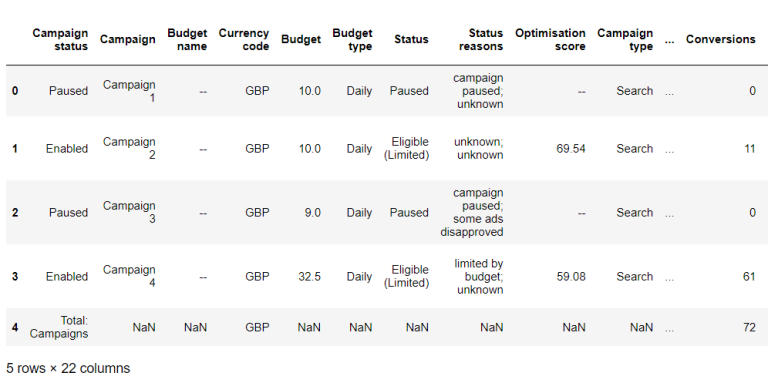
The result will now appear as expected:
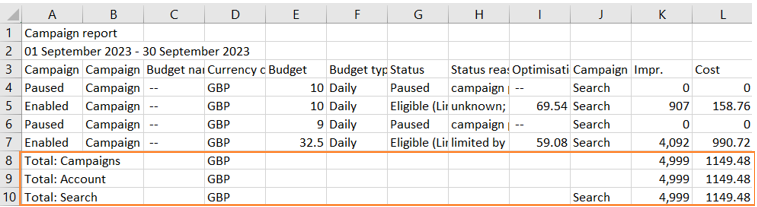
The column headers look right but there is a row with “Total:” at the bottom. If we take a look at the original .csv file then we notice that there are three rows that stare with “Total:”. This is a standard format for .csv files exported from Google Ads.
The pre-calculated totals will affect the results of all the data manipulations with this DataFrame. The following code shows how to remove all the rows containing “Total:”
Here we go, our DataFrame has data from Google Ads and ready for the exploration.